
ChatGPT Data Analysis: A Linguistic Study of Over 1,800 Articles
The Impact ChatGPT has on Human and AI Articles, Both Pre- and Post-ChatGPT

With ChatGPT becoming a household name and a workplace productivity tool, we set out to understand the writing styles of ChatGPT and how it compares to human writers.
There is a lot of conversation around ChatGPT right now. Will it replace jobs? How does copyright impact LLMs (large language models)? We wanted to ask a different question: ChatGPT is influenced by us, but will our writing styles be influenced to change by ChatGPT?
The AI Giant:
Since ChatGPT v3 launched, millions of people have used it. In fact, it is estimated to cost $100,000 per day to run according to MSN. In January, 13 million individual active users utilized it every single day.
As AI approaches usability faster and faster — we're seeing burgeoning uses similar to the Apple slogan "there's an app for that" that are of varying degrees of utility — we start to wonder what groups will be impacted more. Economic Times estimates that computer programming, content writing, the legal industry, and teaching/education will be the most affected. But those are only direct impacts.
We here at MJL wondered about the secondary impacts to one of those industries — content writing.
Imagine a world, if you will, where ChatGPT was being used all around you. Let's assume a subset of your work was AI-generated or AI-informed. Meaning of all the productive work in a space, a larger-than-life actor generates an excessive amount of product compared to other individuals — or even, in some cases, other platforms. Content produced is either (a) written by humans, (b) written by AI/ML, or (c) informed by AI/ML. Without realizing it, plenty of us will fall into the third category. Tools like Grammarly and others are ubiquitous and inform and modify our writing seamlessly.
We wanted to ask the question as to whether the usage of ChatGPT in content writing (focusing on quick content writing — for example, reviews, Top X lists, etc.) might start to experience "linguistic drift" by the presence of this outsized actor.
Will the usage of ChatGPT begin to impact the content humans still write?
Will people who exist in this space be influenced in their word choice by this "silent" actor?
To understand this, we took a few steps to begin our ChatGPT data analysis:
- Ingested a small sample size of data (1800+ articles) before and after ChatGPT became a thing.
- Analyzed those articles for patterns.
- Visualized those patterns in a way our human minds can understand (it's hard for a human brain to understand 500-dimensional data, as you might imagine)
To avoid confusion, "dimensional" in this article is defined as a measurable property, also referred to as a "feature," e.g., the number of sentences or unique words.
For those that want to get to the juicy bits, you can jump to the end. If you want to read more about how we did the work, continue ahead!
Step 1: Ingestion — Let's get some articles
Our approach to visualizing this data utilized dimensionality reduction to visualize complex multi-dimensional data. Human minds, for all their prowess, are still not great at visualizing 500-dimension data, so it's often helpful to "squash" the data into a visualization that our minds can understand.
Dimensionality reduction is the process of taking this very multi-faceted data and "flattening" it to get a different result. Imagine flattening a mountain - you might get a topographical map of the terrain height. Dimensionality is that on steroids.
Doing this process (Kernal PCA implementation for you data nerds out there), we get the following graph:
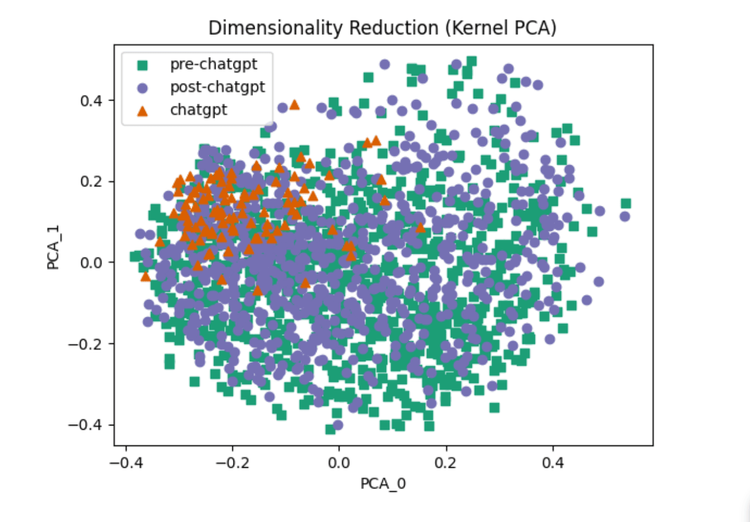
You might notice a few things at the outset. First, Chat GPT differs from "human-attributed" articles - it's a subset that makes complete sense. It was trained on human language, after all. Second, it almost looks like "post-GPT" is migrating towards Chat GPT.
There could be improvements in this sort of approach. First, the data points we used might be correlated, thereby biasing the data somehow. Our next step was to attempt to remove this bias and investigate further.
But before diving into that, let's talk about methodology.
Ingestion Methodology
Collection and preparation of data is often an arduous task. Luckily, we found an excellent tool that helped us collect human-attributed articles. Backfeed uses the Wayback Machine to concatenate all current and historical entries of an RSS feed into a single XML file. Using Backfeed to create RSS feeds turned what could've been weeks of work into several hours of excited waiting as it produced links to many thousands of articles.
Using these XML files, we wrote code to find 100 articles written before ChatGPT was released and 100 articles written after ChatGPT was released for each of our ten sources. At this point, our dataset is in its infancy. It included the articles' text, date of publication, and title. We desired 200 articles, leading to a dataset consisting of 1,711 human-attributed articles. If you're wondering why we didn't have 2,000 articles (200x10), it is because some sources did not have 100 articles before and 100 articles after ChatGPT was released.
The last step of gathering articles was to get articles written by ChatGPT. We set a reasonable goal to acquire 100 ChatGPT articles. Honestly, there is a point in software development where automating a task might take longer than performing the task manually. For this project, we simply typed our requests into the ChatGPT webpage. The prompts given to ChatGPT were to produce an article with the same title as found in 10 articles from each of the ten sources in our human-attributed article dataset. Interestingly, ChatGPT produced articles, in some cases, with very similar content or even more detailed content than the original article. The accuracy of any details, of course, is frequently questionable.
Step 2: Analysis — A slight detour to the realm of linguistics
At this point, we needed to learn about linguistics. For those unaware, linguistics is a very complicated and technical field. We had no delusions of becoming linguistic experts but were just knowledgeable enough to be dangerous. So, we received our introduction to linguistic diversity from Crossley's "Linguistic features in writing quality and development: An overview".
This paper found an excellent set of linguistic analysis tools that would create the rest of our dataset. Our work could not be done without tools like those produced by this team of contributors. The tools we decided to use were the SiNLP, TAALES, and TAASSC. They would provide us with over 500 features numerically describing the linguistic diversity for each article in our dataset.
Step 3: Visualization — everyone gets a graph!
Now, our dataset is complete. It consists of 1,811 articles and over 500 linguistic features. To prepare this dataset for visualization and interpretation, we needed to clean it up. We begin with a process of feature selection and feature extraction.
1
Any feature that does not have linguistic value for this research is removed (e.g., titles, links, ids).
2
We temporarily remove the dependent feature (human-attributed or AI-written) and create a correlation matrix between the independent features. Any feature with an arbitrarily high correlation to another feature is removed, which should result in reduced bias and overfit.
3
We create another correlation matrix but include the dependent feature. Any feature with an arbitrarily low correlation to the dependent feature is removed, which should improve data-processing time at little to no cost in accuracy.
4
We run our now pruned dataset through a Kernel PCA dimensionality reduction process, allowing us to visualize our entire dataset in a 2-dimensional graph.
Figure 1, Dimensional reduction scatter plot showing 3 classes: ChatGPT, pre-ChatGPT, and post-ChatGPT
In the figure above, the two axes you see here (PCA_0 and PCA_1) are created by dimensionality reduction. The three classes of articles (pre-ChatGPT, post-ChatGPT, and ChatGPT) are plotted on these two axes for a simpler visualzation. We compress the hundreds of features down to 2 to visualize the data. It is important to understand that these axes are very abstract. We cannot state the linguistic differences as data points move along either axis. What we can do, however, is visually identify patterns visible within a class and against other classes. We see that there are highly similar results between the pre-ChatGPT and post-ChatGPT classes.
There is also a notable difference between those two classes and articles written by ChatGPT. This might suggest the range of linguistic diversity of articles written by ChatGPT is lower than those written by humans. The significant overlap between human-attributed articles pre- and post-ChatGPT might suggest no significant involvement of ChatGPT in writing these articles. The high overlap between the ChatGPT articles and human-attributed articles is as expected, considering ChatGPT would’ve been trained on text written by humans.
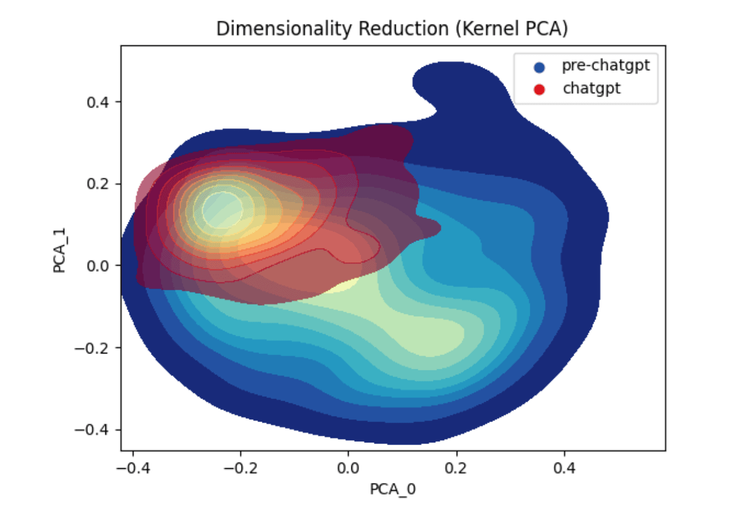
Figure 2: Dimensional reduction kernel density estimate plot showing the two classes of ChatGPT and pre-ChatGPT
Sometimes, showing the data in a different format can be helpful. Figure 2 is a similar graph to Figure 1’s scatter plot. This is a kernel density estimate plot made from the same dimensionally reduced data as in Figure 1. However, this time we are only considering one of the human-made article classes, those written before ChatGPT was released. This is just so the graph is easier to see - this gives us a little better view of the spread of each class and where the bulk of their data points reside.
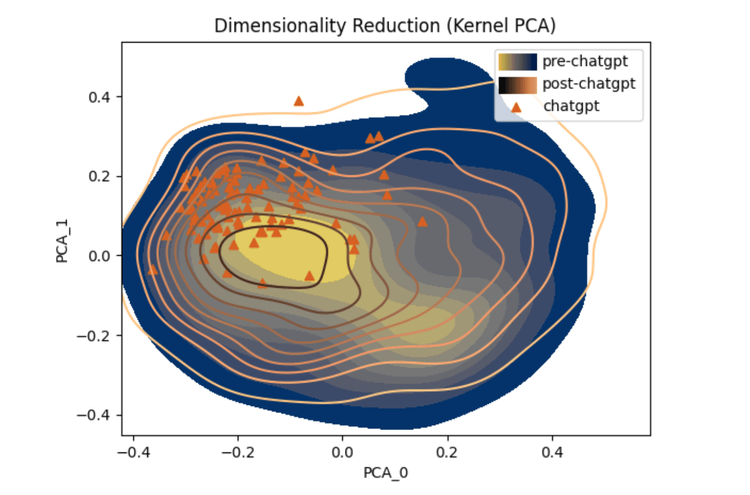
Figure 3: Utilizing three different mechanisms (topography lines, colored areas, and triangular points) to highlight the overlapping nature of the data
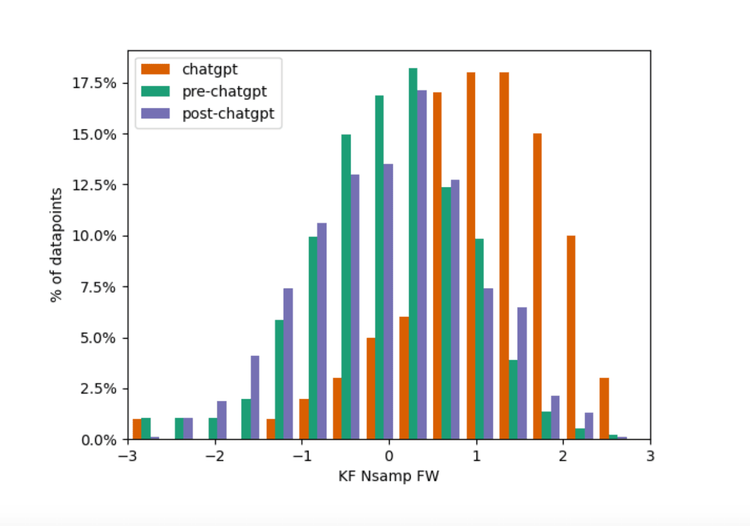
Figure 4
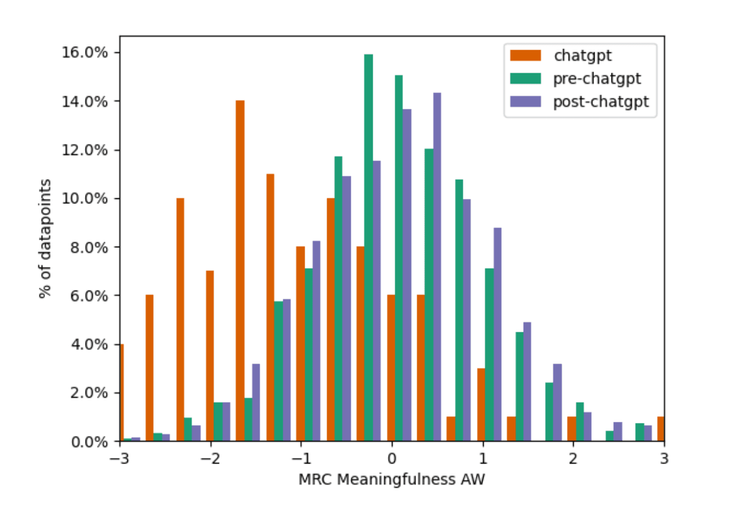
Figures 5
Both figures 4 & 5: Histograms that highlight the difference between the classes for a single feature
Figures 4 and 5 show some actual linguistic features that begin to differentiate between humans and ChatGPT. It is, again, important to note that ChatGPT does learn from humans. So, we should not expect ChatGPT to write in ways humans cannot. But, ChatGPT can tend to write in ways that a smaller subset of the human population does. The two features shown in Figures 4 and 5 drive towards this as the average and spread of these linguistic features diverge.
On the other hand, ChatGPT is similar to human writers in many other ways:
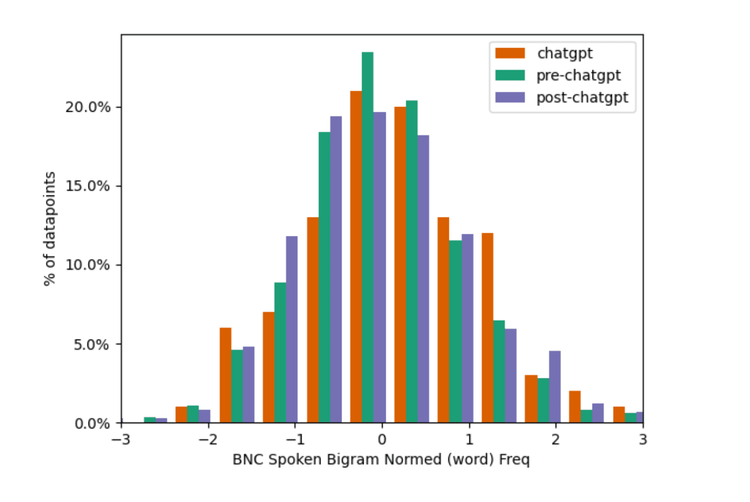
Figure 6
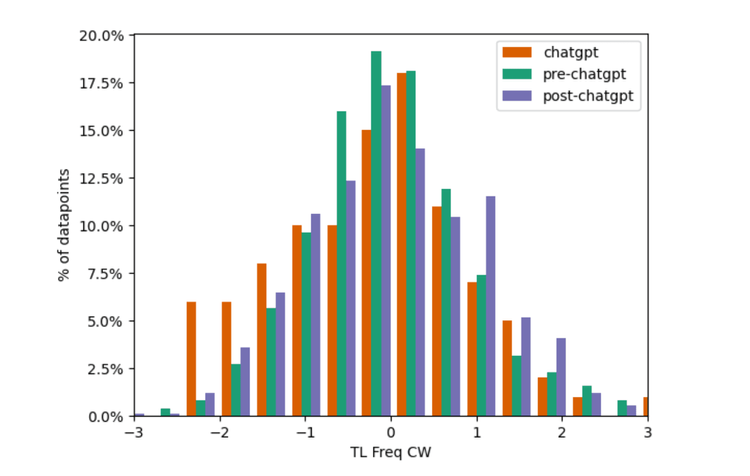
Figure 7
Both 6 & 7: histograms that highlight the similarity between the classes for a single feature
With figures 6 and 7, we see linguistic features where articles written by ChatGPT show high similarity to articles written by humans. As mentioned previously, ChatGPT does learn from humans, and we should expect many similarities between human-attributed and ChatGPT-written articles.
Conclusion
ChatGPT is a tool built by humans and trained on human data. ChatGPT is monstrously huge (175 billion parameters) regarding the data it ingests and processes. By collecting a sample size of 1.8k+ articles, we wanted to see if there has been an impact on articles written in the post-ChatGPT internet and whether or not the authors of that article utilized ChatGPT in their process.
Our investigation and results highlight that while a naive viewer of the data may see some drift between our post-ChatGPT world and pre-ChatGPT, it is by no means a massive shift yet. While some sites have been caught using ChatGPT, it's much harder to see or predict a difference in human authors who are simply influenced by the presence of the massive chatbot.
At the same time, usage of the tool continues to climb. Like many other tools before, it will likely have an outsized impact on written content. Looking back, when the squiggly line first appeared in email editors, emails suddenly became better written —except from that Nigerian prince, of course.
We're looking forward to seeing how new tools like ChatGPT will shift how we work.
Ready to put AI to work for your company?
You can integrate ChatGPT and AI into your business in many ways to create seamless workflows and faster turnaround times. Want to explore the opportunities that AI can form within your organization? Let's talk.
Be sure to read How Monkeyjump Labs created a ChatGPT-powered internal chat bot for our company in 8 hours.